This article explains how to optimize performance for an Amazon Redshift data warehouse that uses a star schema design. Many of these techniques will also work with other schema designs. We’ll talk about considerations for migrating data, when to use distribution styles and sort keys, various ways to optimize Amazon Redshift performance with star schemas, and how to identify and fix performance bottlenecks.
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. Amazon Redshift offers you fast query performance when analyzing virtually any size dataset using the same business intelligence applications you use today. Amazon Redshift uses many techniques to achieve fast query performance at scale, including multi-node parallel operations, hardware optimization, network optimization, and data compression. At the same time, Amazon Redshift minimizes operational overhead by freeing you from the hassle associated with provisioning, patching, backing up, restoring, monitoring, securing, and scaling a data warehouse cluster. For a detailed architecture overview of the Amazon Redshift service and optimization techniques, see the Amazon Redshift system overview.
To get in depth knowledge on AWS you can enroll for free live demo AWS Online Course
Many business intelligence solutions use a star schema or a normalized variation called a snowflake schema. Such solutions typically have tooling that depends upon a star schema design. Star schemas are organized around a central fact table that contains measurements for a specific event, such as a sold item. The fact table has foreign key relationships to one or more dimension tables that contain descriptive attribute information for the sold item, such as customer or product. Snowflake schemas extend the concept by further normalizing the dimensions into multiple tables. For example, a product dimension may have the brand in a separate table. For more information, see star schema and snowflake schema.
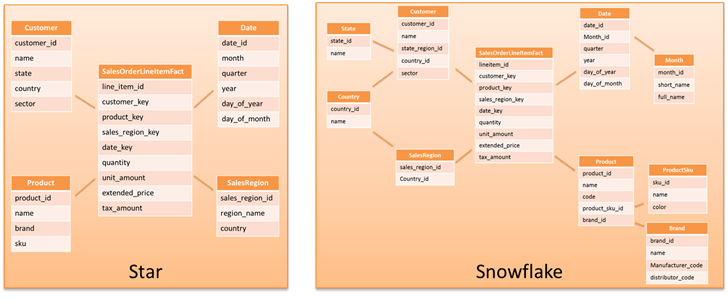
The Amazon Redshift design accommodates all types of data models, including 3NF, denormalized tables, and star and snowflake schemas. You should start from the assumption that your existing data model design will just work on Amazon Redshift. Most customers experience significantly better performance when migrating their existing data models to Amazon Redshift largely unchanged, though you should test for performance using either the actual or a representative dataset to ensure that your data model design and query patterns perform well before putting the workload into production.
Optimizations for Star Schemas
Amazon Redshift automatically detects star schema data structures and has built-in optimizations for efficiently querying this data. You also have a number of optimization options under your control that affect query performance whether you are using a star schema or another data model. The following sections explain how to apply these optimizations in the context of a star schema.
Primary and Foreign Key Constraints
When you move your data model to Amazon Redshift, you can declare your primary and foreign key relationships. Even though Amazon Redshift does not currently enforce these relationships, the query optimizer uses them as a hint when it analyzes a query. In certain circumstances, Amazon Redshift uses this information to optimize the query by eliminating redundant joins. Generally, the query optimizer detects redundant joins without constraints defined if you keep statistics up to date by running the ANALYZE command as described later in this article.
Learn for more AWS Interview Questions
To avoid unexpected query results, you should ensure that the data being loaded does not violate foreign key constraints and that primary key uniqueness is maintained by enforcing no duplicate inserts. For example, if you load the same file twice with the copy command, Amazon Redshift does not enforce primary keys and will duplicate the rows in the table. This duplication violates the primary key constraint. For more information, see Defining constraints in the Amazon Redshift Database Developer Guide.
Distribution Styles
The following distribution style guidelines are not hard-and-fast rules but rather a good place to begin with optimizations. You should test and experiment to find the right balance between considerations such as query frequency, complexity, and criticality when deciding which distribution style and which distribution keys to use. If you find that you have some complex, long-running queries that may back up simpler, frequently used queries, then consider using the Amazon Redshift workload management feature to partition the queries into different queues. For more information, see Workload management.
Using a distribution key is a good way to optimize the performance of Amazon Redshift when you use a star schema. If a distribution key is not defined for a table, data is spread equally across all nodes in the cluster to ensure balanced performance across nodes; however, in many cases, simply distributing data equally does not optimize performance for each node or slice in the cluster.
A good distribution key distributes data relatively evenly across nodes while also collocating joined data to improve cluster performance. If you are using a star schema, follow these distribution key guidelines to optimize Amazon Redshift performance across nodes:
- Define a distribution key for your fact table as the foreign key to one of the larger dimension tables.
- Identify frequently joined dimension tables with slowly changing data that are not joined with the fact table on a common distribution key. These are good candidates for the distribution style of ALL.
- Choose the primary (or surrogate) key as the distribution key for remaining dimension tables.
A compute node is divided into slices. The number of slices is equal to the number of processor cores on the node. A slice is the unit at which data is distributed within the cluster. For more information about the elements of the Amazon Redshift data warehouse architecture, see Data warehouse system architecture in the Amazon Redshift Database Developer Guide.
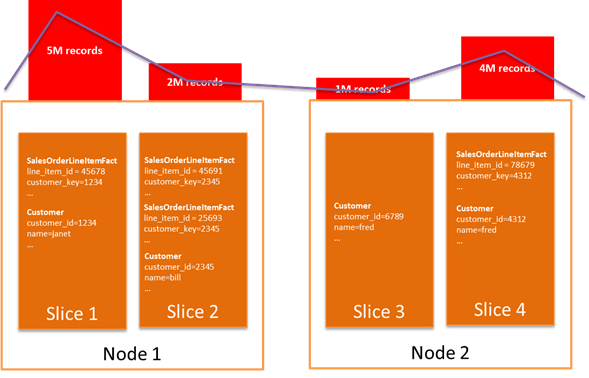
If you have multiple tables with distribution keys, then the row data with the same distribution key value resides on the same slice, regardless of which table the data comes from. This occurs because Amazon Redshift hashes the distribution key value to determine the slice for the data in each table. Thus the same key value results in the same hash regardless of the table. In the preceding example, the Sales Order LineItemFact table has a distribution key of customer_key, and the Customer dimension table has a distribution key of customer_id. The data where customer_key equals customer_id will be located on the same slice in a node.
As illustrated in the following diagram, when Customer and Sales Order LineItem Fact are joined on customer_id and customer_key, then the joined row data are located on the same slice, eliminating any inter-node data movement to satisfy the join.

When you choose distribution keys, you should optimize for your most common joins while striving to spread data relatively evenly across the cluster for your tables. In the preceding example, if you were doing an operation on sales order, then Slice 2 needs to process two sales order lines while Slice 3, representing a customer with no orders, will do no work.
Figure 3 further illustrates how choosing a poor distribution key that excessively skews (unevenly distributes) data can degrade performance. In this scenario, when several large customers purchase a large proportion of the products from your company, distributing the fact table by customer_key results in a skew. The blue line represents compute utilization on each node.
In many cases, you may need to experiment with your data to see if the resulting distribution is reasonable. Sometimes a distribution key based upon the size of the joined tables seems like a good choice, but it ends up being a poor choice when you take skew into account. A common case is when two larger tables are joined on a particular column but the value in one of the tables is often null. For example, say you choose user_id for a distribution key in a table of web log file entries and a table of user profiles that are often joined, where the user_id in the log table is null if the user is not logged in. On the surface, user_id seems like a good choice, because both tables are large. However, the log table ends up with a large number of rows concentrated on the null column value, resulting in severe skew on one slice. For examples that show how to determine if your data is evenly distributed, see Distribution examples.
Amazon Redshift also has a distribution style of ALL. This distribution style replicates the table data once per node. Because the copy is used by all slices on the node, this distribution style has an impact on available storage. This distribution style is suitable for dimension tables that fit the following criteria:
- Reasonably large in size – You should experiment and measure the impact of this distribution style. Redshift moves data between nodes efficiently, so very small tables will not see significant gains.
- Slowly changing dimension data – Loading data into tables with a distribution style of ALL is expensive, but it can be worth it if the data is updated infrequently. Frequently changing dimension data with a distribution style of ALL increases load times significantly.
- Frequently joined on a column that is not a common distribution key – Typically this occurs because there is a larger dimension table joined with the fact table that uses a different distribution key or because the join key causes uneven data distribution when chosen as the distribution key.
Typically a star schema has a large fact table and numerous, comparatively smaller dimension tables. You can follow these steps to optimize the distribution choices for optimized table joins:
- Identify large dimension tables used in joins.
- Choose the large dimension that is most frequently joined as indicated by your query patterns.
- Follow the guidelines in the preceding section to make sure that the foreign key to the dimension in the fact table gives relatively even distribution across your facts and that the primary/surrogate key for the dimension table is also relatively evenly distributed. If distribution is not relatively even, choose a different dimension.
- Use the foreign key to the identified dimension as your fact table distribution key, and use the primary key in the dimension table as your dimension table distribution key.
- Identify dimension tables that are suitable for a distribution style of ALL as described earlier in this article.
- For the remainder of your dimension tables, define the primary key as the distribution key. The primary key does not typically exhibit significant data skew. If it does, then don’t define a distribution key.
- Test your common queries and use the EXPLAIN command for any queries that need further tuning. For information about the EXPLAIN command, see the EXPLAIN command documentation.
Amazon Redshift is intelligent about minimizing the internode transmission of data to satisfy a query when it does joins, both by ordering how it executes elements of the join and by using techniques like hashing to minimize internode data transfer. Examples and techniques for performing joins are explained in EXPLAIN operators, Join examples, and the EXPLAIN command documentation. For more information about choosing a distribution key, see Choosing a data distribution style in the Amazon Redshift Database Developer Guide.
Sort Keys
You can improve query performance on Amazon Redshift by defining a sort key for each of your tables. A sort key determines how data is stored on disk for your table. The primary way a sort key improves query performance is by optimizing I/O operations when columns defined in the sort key are used in the where clause as a filtering condition (often called a filter predicate) or in operations like group by or order by. You should identify the most frequently used column for filtering and ordering operations in your dimension and fact tables as the sort key for each table.
If more than one column is typically used as a filter predicate, you can improve filtering efficiency by specifying multiple columns as part of the sort key. For example, let’s say the color and size columns are both specified in the sort key. If you filter on color = ‘red’ and size = ‘xl’, the use of color and size in the filtering and sort key makes the query execution more efficient. If you filter on color = ‘red’, the sort key will still be used to make the query more efficient since color is part of the leading key (the combination of the leading sort key columns). On the other hand, if you filter only for size=’xl’, then the sort key will not be used in the query execution because size is not part of the leading key. If the leading key is relatively unique (often called high cardinality), adding additional columns to your sort key will have little impact on query performance but will have a potential maintenance cost.
The sort key can have limited positive impact in other areas such as influencing more efficient joins and aggregations; however, the impact is not as reliable as the distribution key. For more information about defining sort keys, see Choosing sort keys in the Amazon Redshift Database Developer Guide.
Data Compression
Amazon Redshift optimizes the amount and speed of data I/O by using compression and purpose-built hardware. By default, Amazon Redshift analyzes the first 100,000 rows of data to determine the compression settings for each column when you copy data into an empty table. You can usually rely upon the Amazon Redshift logic to automatically choose the optimal compression type for you, but you can also choose to override these settings. Leaving compression turned on helps your queries to perform faster and minimizes the amount of physical storage your data consumes, thus allowing you to store larger datasets in your cluster. We strongly recommend that you use automatic compression. For more information about controlling compression options, see Choosing a column compression type.







{kind=link}